Overview
Ocean Read Atlas (ORA) is a web service to explore the biogeography of one or several sequences in a marine environmental context. ORA enables to query DNA sequences against an index of read sequences and determine the similarity to each indexed sample. The similarity between a query \(q\) and each of the indexed samples \(q_i\) is approximated by the ratio of k-mers (words of fixed length \(k\)) shared between \(q\) and \(q_i\).
ORA is currently implemented with the Tara Oceans project dataset and eleven plankton size fractions from 0 to 2000 µm can be queried.
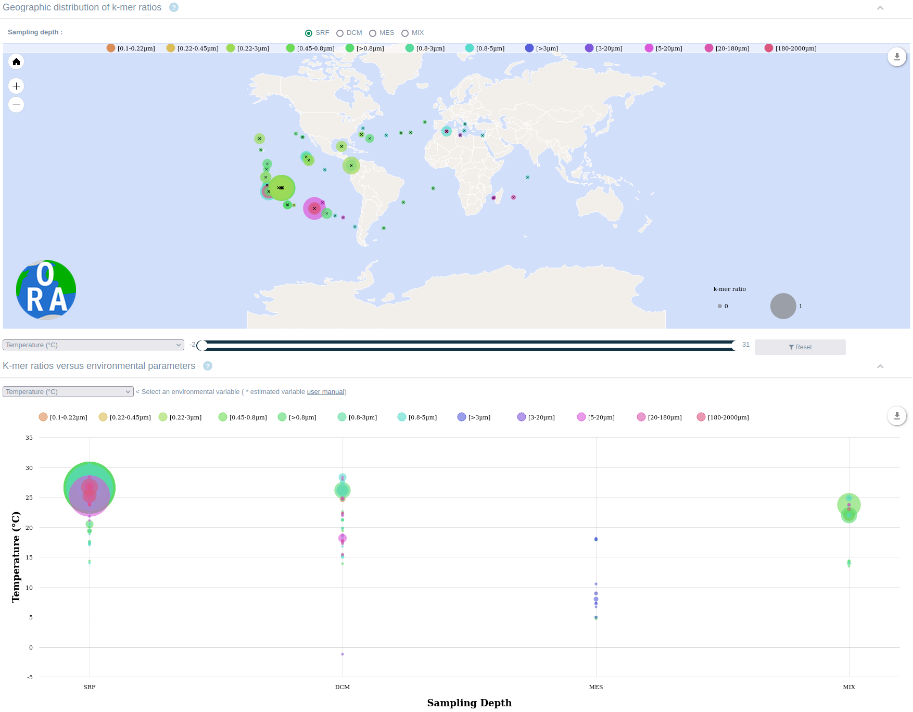
When a query is performed, results are shown using a worldwide map in which k-mers ratio is depicted thanks to colored circle (see Figure 1). An interactive slider above the map allows user to get selected samples according to a particular environmental parameter range displayed on the map.
In addition, each sample comes with numerous metadata such as its localisation, sea depth, pH, temperature, salinity, etc. Hence, results also enable to summarize on plots, how the query correlates with any chosen environmental parameter.
Finally, the results can be downloaded as a table file or under several image format files.
The user can use one or more sequences to query the index and determine the similarity of each of the 1,393 indexed samples to its query. The original index was created using open source softwares kmtricks and kmindex.
If you use this web service, please cite:
- T. Lemane, N. Lezzoche, J. Lecubin, E. Pelletier, M. Lescot, R. Chikhi, P. Peterlongo (2024). Indexing and real-time user-friendly queries in terabyte-sized complex genomic datasets with kmindex and ORA. Nature Computational Science 10.1038/s43588-024-00596-6
Web application : https://ora.mio.osupytheas.fr/
Source code : https://gitlab.osupytheas.fr/ocean_atlas/ora
Contact : oceanreadatlas@mio.osupytheas.fr